Benchmark¶
The following figure shows the prediction throughput of treelite and XGBoost, measured with various batch sizes.

(Get this plot in SVG, PNG, High-resolution PNG)
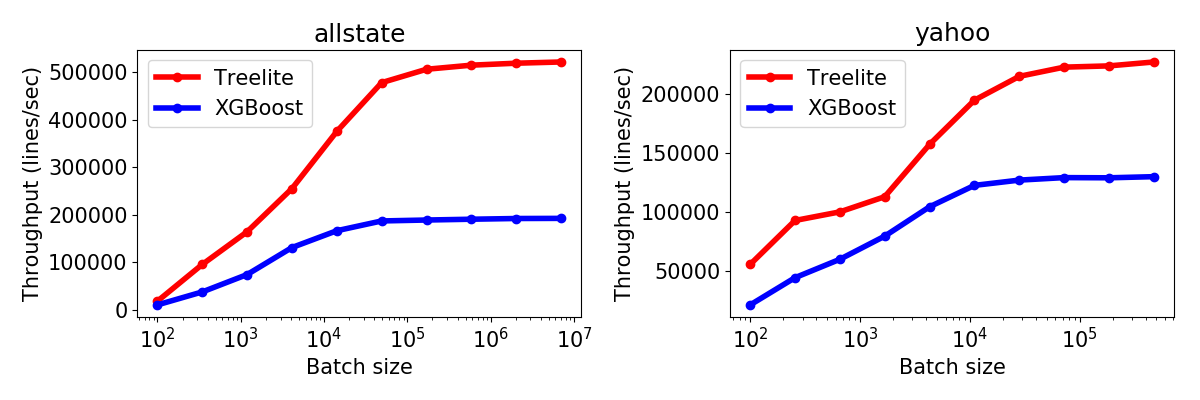{kind=link}
{kind=link}
System configuration. One AWS EC2 instance of type c4.8xlarge was used. It consists of the following components:
- CPU: 36 virtual cores, 64-bit
- Memory: 60 GB
- Storage: Elastic Block Storage (EBS)
- Operating System: Ubuntu 14.04.5 LTS
Datasets. Two datasets were used.
Methods. For both datasets, we trained a 1600-tree ensemble using XGBoost.
Then we made predictions on batches of various sizes that were sampled randomly
from the training data. After running predictions using treelite and XGBoost
(latter with xgboost.Booster.predict()), we measured throughput as
the number of lines predicted per second.
Actual measurements. You may download the exact measurements using the following links: allstate.csv yahoo.csv
Caveats. For datasets with a small number of features (< 30) and few missing values, treelite may not produce any performance gain. The higgs dataset is one such example:

(Get this plot in SVG, PNG, High-resolution PNG)
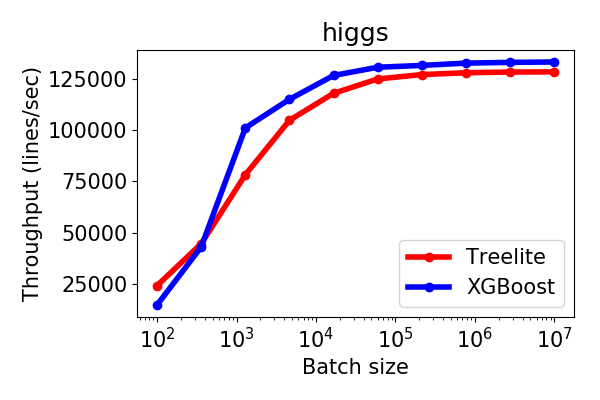{kind=link}
{kind=link}
We are investigating additional optimization strategies to further improve performance.